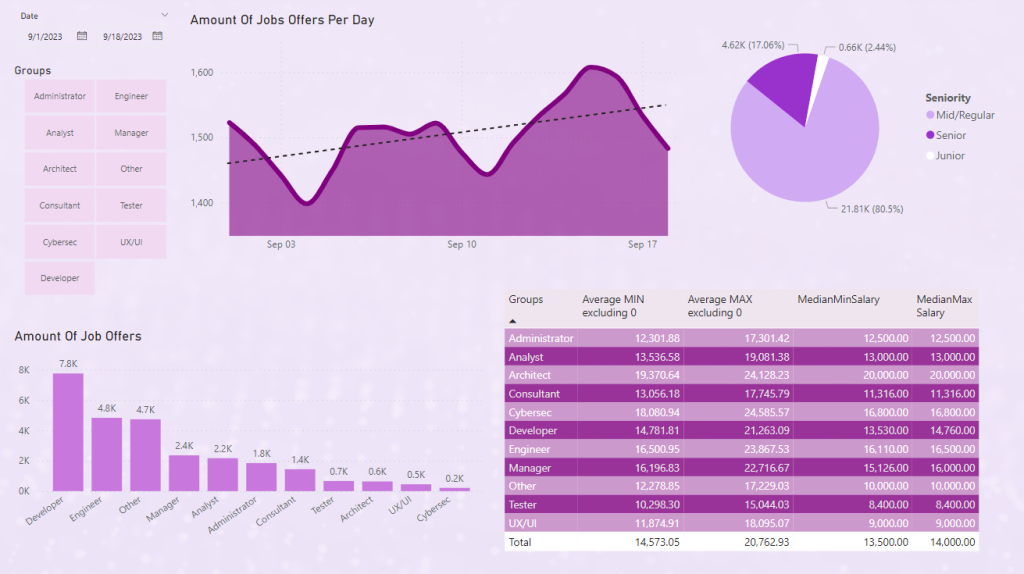
Script deletes all existing CSV files in the directory. Then scrapes job offers from pracuj.pl for remote work. Data such as job title, company name, and salary are saved to a CSV file. The script then loads the CSV file and processes the salary column, converting the values to minimum and maximum salary. Ranks the jobs based on the title and adds that classification as a new column to the DataFrame, then saves the resulting DataFrame to a new CSV file.
Python
import os
import csv
import pandas as pd
import requests
import re
from bs4 import BeautifulSoup
from datetime import datetime
import glob
def scrape_jobs(url):
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
job_offers = soup.find_all('div', class_='listing_c7z99rl')
for offer in job_offers:
title = offer.find('h2', class_='listing_buap3b6').text
company = offer.find('h4', class_='listing_eiims5z size-caption listing_t1rst47b').text
salary_element = offer.find('span', class_='listing_sug0jpb')
if salary_element:
salary = salary_element.text
else:
salary = 'None'
csv_writer.writerow([title, company, salary])
def convert_salary(salary):
if isinstance(salary, str):
if salary == 'None':
return salary, 'None'
netto = 'net' in salary.lower()
salary = salary.split('/')[0]
salary = re.sub(r'\s+', '', salary)
salary = re.sub(r'[^\d.–]+', '', salary)
if '–' in salary:
salary_range = salary.split('–')
try:
min_salary = float(salary_range[0])
max_salary = float(salary_range[1])
if netto:
min_salary *= 1.23
max_salary *= 1.23
if min_salary < 1000:
min_salary *= 40
if max_salary < 1000:
max_salary *= 40
return min_salary, max_salary
except ValueError:
return None, 'None'
else:
try:
min_salary = float(salary)
if netto:
min_salary *= 1.23
if min_salary < 1000:
min_salary *= 40
return min_salary, 'None'
except ValueError:
return None, 'None'
else:
return None, 'None'
def classify_title(title):
title = title.lower()
if "developer" in title:
return "Developer"
elif "engineer" in title:
return "Engineer"
elif "analyst" in title or "analityk" in title:
return "Analyst"
elif "architect" in title:
return "Architect"
elif "admin" in title or "linux" in title or " it" in title:
return "Administrator"
elif "manager" in title or "head" in title or "kierownik" in title or "lead" in title:
return "Manager"
elif "consultant" in title or "konsultant" in title:
return "Consultant"
elif "cyber" in title or "bezpie" in title or "sec" in title:
return "Cybersec"
elif "test" in title:
return "Tester"
elif "ux" in title or "ui" in title:
return "UX/UI"
else:
return "Other"
for file in glob.glob("*.csv"):
os.remove(file)
with open('job_offers.csv', mode='w', encoding='utf-8') as csv_file:
csv_writer = csv.writer(csv_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
csv_writer.writerow(['Title', 'Company', 'Salary'])
base_url = 'https://www.pracuj.pl/praca/praca%20zdalna;wm,home-office?cc=5015%2C5016&pn='
for page_number in range(1, 60):
url = base_url + str(page_number)
scrape_jobs(url)
df = pd.read_csv('job_offers.csv')
df[['MIN', 'MAX']] = df['Salary'].apply(convert_salary).apply(pd.Series)
df.drop(columns=['Salary'], inplace=True)
df['Date'] = datetime.now().strftime('%Y-%m-%d')
df.to_csv('job_offers_salary.csv', index=False)
df = pd.read_csv('job_offers_salary.csv')
df['Groups'] = df['Title'].apply(classify_title)
df.to_csv('jobs.csv', index=False)I have set daily job in crontab on my server to gather data and import it to mariaDB for future analysis.
Bash
30 12 * * * mysqlimport --ignore-lines=1 --fields-terminated-by=',' --fields-optionally-enclosed-by='"' --silent --local -u datauser PRACUJ_PL /path/to/file/jobs.csv
05 12 * * * /usr/bin/python3 /path/to/file/scrapepracuj_v2.py